
最近想着自己搭建一个api图床,而Cloudflare储存费很便宜,免费10GB的储存加上完全不收出口流量费,加上域名托管有一大堆免费服务,简直是互联网赛博大善人,在这里狠狠推荐一波Cloudflare R2。
一、注册Cloudflare和创建R2分布式对象存储
首先是注册Cloudflare账号,然后登录控制台(https://dash.cloudflare.com/),然后点击左边的R2对象存储。
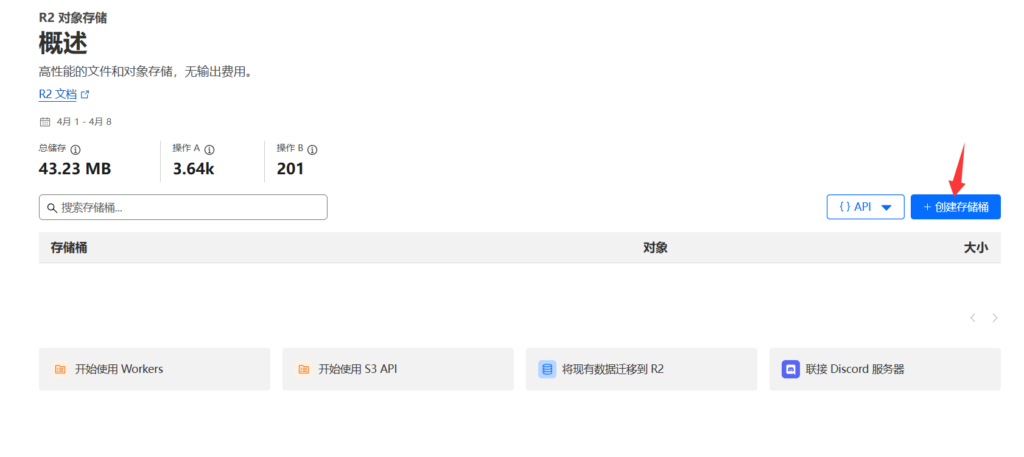
点进去R2之后,需要绑定信用卡,MaterCard/Visa都行,不支持银联,但是可以绑定PayPal。点那个新增储存桶,给个名称,选择地区是亚太地区(离自己最近的地区)。
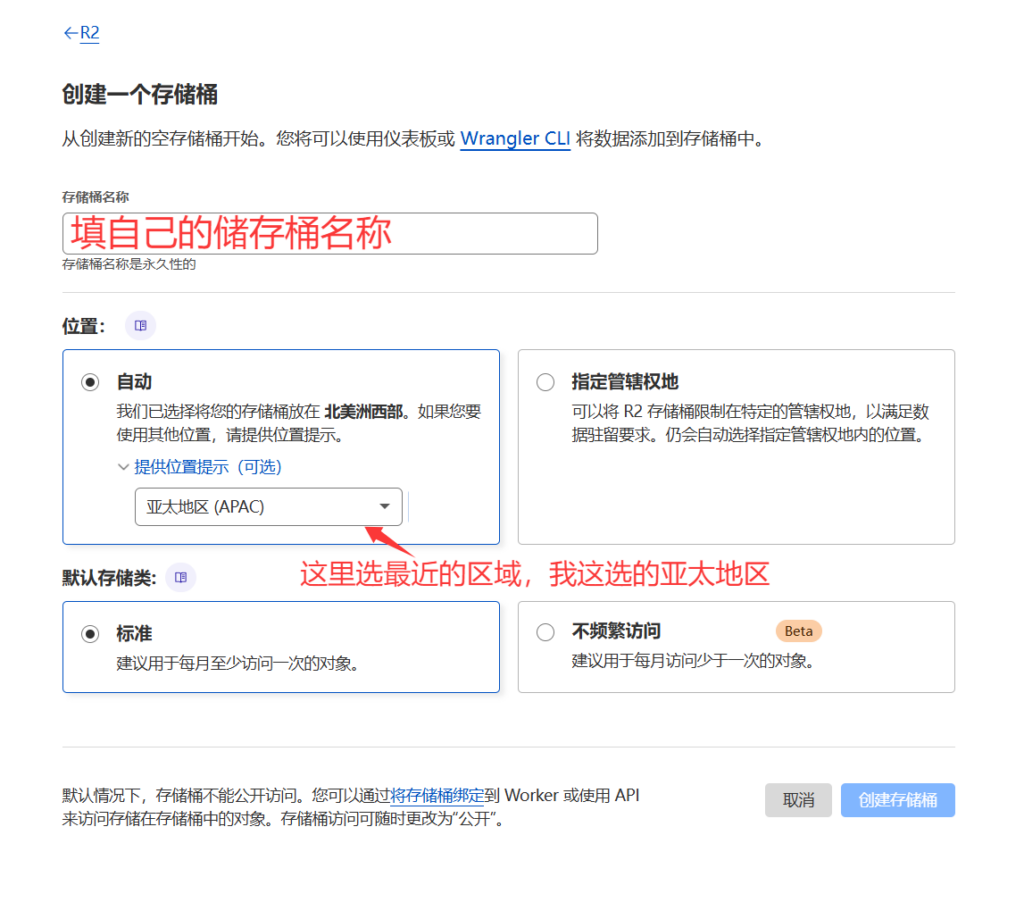
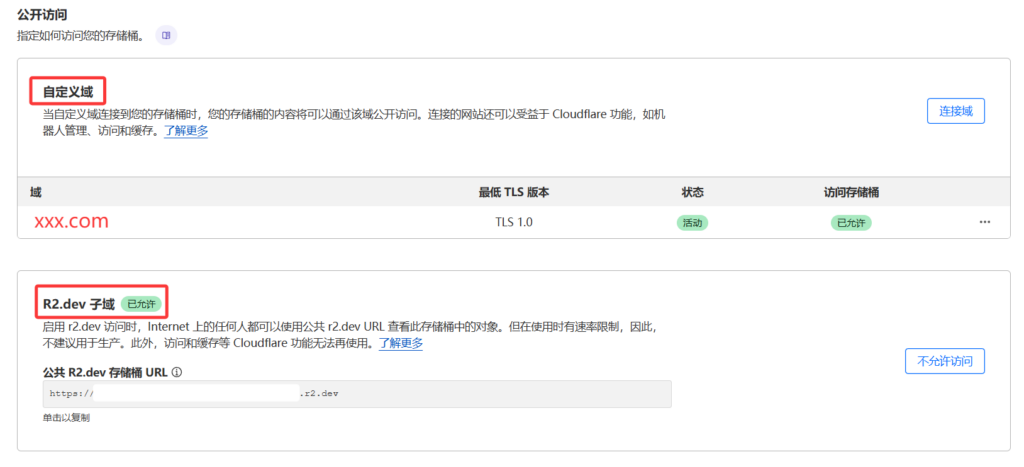
点设置,在公开访问里打开R2.dev子域,允许访问,然后就会生成一串网址,这个网址就是你访问的网址了,如果你上传了一张图片,那么该访问“网址/图片名称”就可以访问到该图片了。但是这个网址只能通过科学的手段才可以访问到,直连是连接不上的,为了方便起见,建议使用自定义域的形式(自己的域名和他那一串网址CNAME一下),如果你有自己的域名并且域名托管在cloudflare上了,那么可以在自定义域那里设置一下。设置好后,你自己的“域名/图片名称”也可以访问该图片,而且不需要科学就可以直接访问到了。
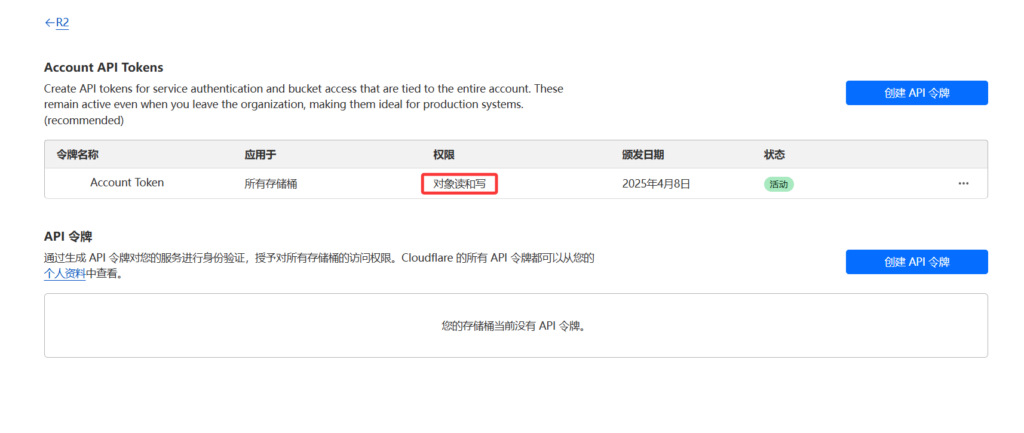
这些玩意都设置好了,就可以上传文件到储存桶咯。我的文件比较多,因此我选择用api上传,回到R2储存界面,选择管理API,创建API令牌,给个名字,权限为对象读和写,记录好access_key和secret_access_key因为这俩不会再显示,如果忘了可以删了重新创建。还是回到R2储存界面,选择R2与API配合使用,记录下面的那串网址,一会这三个记录的要用,到此Cloudflare的储存设置就全部结束了。

二、文件批量上传的Python脚本
因为我想把一个文件夹里所有文件都上传到Cloudflare上,最开始选择的是PicGo作为上传工具,但是批量上传有点麻烦,就搞了个脚本,主要实现的功能有(AI总结的):
1. 智能文件上传系统
- 自动去重检测:基于文件内容哈希(SHA256)和文件名双重校验,避免重复上传
- 断点续传支持:内置上传中断恢复机制,意外退出时自动清理未完成的上传
- 大文件优化:50MB以下文件禁用分段上传,减少请求次数
- 失败自动重试:网络波动时自动重试最多3次
2. 精准同步删除机制
- 自动检测删除:实时比对本地与云端文件状态
- 安全同步清理:本地删除的文件会自动从R2移除,保持两端一致
- 操作审计追踪:所有删除操作记录详细日志,便于追溯
3. 本地化管理体系
- 轻量级数据库:使用SQLite记录所有文件状态,快速查询比对
- 完整操作日志:标准化记录每次操作的时间戳、文件大小、哈希值等关键信息
- 可视化统计:实时显示上传/跳过/删除/失败的详细统计
反正就是本地给个文件夹,里面放好要上传的文件,运行一下就行了,本地删除云端跟着也删了,下面是代码,运行之前首先需要pip install一下。
pip install boto3
pip install tqdmimport boto3
import os
import time
import sqlite3
from datetime import datetime
import hashlib
from tqdm import tqdm
import atexit
from botocore.config import Config
from typing import Optional, Dict, Any
from boto3.s3.transfer import TransferConfig
# R2配置区(填填这里)
R2_CONFIG: Dict[str, Any] = {
"aws_access_key_id": "", #api的keyid
"aws_secret_access_key": "", #api的秘钥
"endpoint_url": "", #之前记录的那个网址
"region_name": "auto",
"config": Config(
retries={'max_attempts': 3, 'mode': 'standard'},
connect_timeout=10,
read_timeout=30
)
}
BUCKET_NAME: str = '' #你创建的储存桶的名字
LOCAL_DIR: str = r'E:\xx\' #填上你本地要上传的文件夹
TARGET_R2_FOLDER: str = 'xxx' #上传到Cloudflare的xxx文件夹里
CUSTOM_DOMAIN: str = '' #你的自定义域名
LOG_FILE: str = 'uploaded_links.log'
MAX_SINGLE_UPLOAD_SIZE: int = 50 * 1024 * 1024 # 50MB以下禁用分段上传,可以自己调整
class R2Uploader:
def __init__(self) -> None:
self.s3 = boto3.client('s3', ** R2_CONFIG)
self.db_file: str = os.path.join(os.path.dirname(__file__), "uploaded_files.db")
self.current_upload_key: Optional[str] = None
self._register_cleanup()
self._init_db()
self._init_log_file()
self.stats: Dict[str, int] = {
'total': 0,
'uploaded': 0,
'skipped': 0,
'failed': 0,
'deleted': 0
}
self.transfer_config = TransferConfig(
multipart_threshold=MAX_SINGLE_UPLOAD_SIZE + 1,
use_threads=False
)
def _register_cleanup(self) -> None:
atexit.register(self._cleanup_current_upload)
def _init_db(self) -> None:
"""初始化数据库"""
with sqlite3.connect(self.db_file) as conn:
conn.execute("PRAGMA journal_mode=WAL")
conn.execute("""
CREATE TABLE IF NOT EXISTS uploaded_files (
id INTEGER PRIMARY KEY AUTOINCREMENT,
filename TEXT NOT NULL COLLATE NOCASE,
file_hash TEXT NOT NULL UNIQUE,
upload_time TEXT NOT NULL,
s3_key TEXT NOT NULL UNIQUE,
file_size INTEGER NOT NULL,
public_url TEXT NOT NULL UNIQUE
)
""")
conn.execute("CREATE INDEX IF NOT EXISTS idx_hash ON uploaded_files(file_hash)")
conn.execute("CREATE INDEX IF NOT EXISTS idx_filename ON uploaded_files(filename)")
@staticmethod
def _init_log_file() -> None:
if not os.path.exists(LOG_FILE):
with open(LOG_FILE, 'x', encoding='utf-8') as f:
f.write("-- 图片上传记录\n-- 格式: 时间戳|文件名|文件大小(KB)|访问链接|文件哈希|操作类型\n\n")
@staticmethod
def _calculate_hash(file_path: str) -> str:
sha256 = hashlib.sha256()
try:
with open(file_path, 'rb') as f:
for chunk in iter(lambda: f.read(8192), b''):
sha256.update(chunk)
return sha256.hexdigest()
except (IOError, OSError) as e:
raise RuntimeError(f"文件哈希计算失败: {str(e)}")
def _is_file_uploaded(self, file_hash: str, filename: str) -> bool:
with sqlite3.connect(self.db_file) as conn:
cursor = conn.cursor()
cursor.execute("""
SELECT 1 FROM uploaded_files
WHERE file_hash = ? OR filename = ? COLLATE NOCASE
LIMIT 1
""", (file_hash, filename))
return cursor.fetchone() is not None
def _record_operation(self, filename: str, file_hash: str, s3_key: str,
file_size: int, public_url: str, operation: str) -> bool:
try:
with sqlite3.connect(self.db_file) as conn:
if operation == "UPLOAD":
conn.execute("BEGIN IMMEDIATE TRANSACTION")
conn.execute(
"INSERT OR REPLACE INTO uploaded_files VALUES (NULL, ?, ?, ?, ?, ?, ?)",
(filename, file_hash,
datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
s3_key, file_size, public_url)
)
conn.commit()
elif operation == "DELETE":
conn.execute("DELETE FROM uploaded_files WHERE filename = ?", (filename,))
conn.commit()
with open(LOG_FILE, 'a', buffering=1, encoding='utf-8') as f:
f.write(
f"{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}|"
f"{filename}|"
f"{file_size / 1024:.1f}KB|"
f"{public_url}|"
f"{file_hash}|"
f"{operation}\n"
)
return True
except sqlite3.Error as e:
print(f"数据库操作失败: {str(e)}")
return False
def _cleanup_current_upload(self) -> None:
if self.current_upload_key:
try:
self.s3.delete_object(Bucket=BUCKET_NAME, Key=self.current_upload_key)
except self.s3.exceptions.NoSuchKey:
pass
except Exception as e:
print(f"清理上传残留失败: {str(e)}")
def _safe_upload(self, file_path: str, s3_key: str) -> bool:
self.current_upload_key = s3_key
success = False
try:
with open(file_path, 'rb') as f:
self.s3.upload_fileobj(
f,
BUCKET_NAME,
s3_key,
Config=self.transfer_config,
ExtraArgs={'ContentType': 'image/png'}
)
success = True
except self.s3.exceptions.S3UploadFailedError as e:
print(f"S3上传失败: {str(e)}")
except (IOError, OSError) as e:
print(f"文件读取错误: {str(e)}")
except Exception as e:
print(f"未知上传错误: {str(e)}")
raise
finally:
self.current_upload_key = None
return success
def _sync_deleted_files(self) -> None:
"""同步删除本地已不存在的文件"""
local_files = {f for f in os.listdir(LOCAL_DIR)
if os.path.isfile(os.path.join(LOCAL_DIR, f))}
with sqlite3.connect(self.db_file) as conn:
cursor = conn.cursor()
cursor.execute("SELECT filename, s3_key, file_hash, file_size, public_url FROM uploaded_files")
db_records = cursor.fetchall()
for filename, s3_key, file_hash, file_size, public_url in db_records:
if filename not in local_files:
try:
self.s3.delete_object(Bucket=BUCKET_NAME, Key=s3_key)
if self._record_operation(filename, file_hash, s3_key, file_size, public_url, "DELETE"):
self.stats['deleted'] += 1
print(f"已同步删除: {filename}")
except Exception as e:
print(f"删除同步失败: {filename} - {str(e)}")
def upload(self) -> None:
try:
print("正在同步删除操作...")
self._sync_deleted_files()
files = [f for f in os.listdir(LOCAL_DIR)
if os.path.isfile(os.path.join(LOCAL_DIR, f))]
self.stats.update({
'total': len(files),
'uploaded': 0,
'skipped': 0,
'failed': 0
})
with tqdm(total=len(files), desc="上传文件中", unit="文件") as pbar:
for filename in files:
file_path = os.path.join(LOCAL_DIR, filename)
try:
file_size = os.path.getsize(file_path)
s3_key = f"{TARGET_R2_FOLDER}/{filename.replace('\\', '/')}"
public_url = f"{CUSTOM_DOMAIN}/{filename}"
file_hash = self._calculate_hash(file_path)
if self._is_file_uploaded(file_hash, filename):
self.stats['skipped'] += 1
pbar.update(1)
continue
start_time = time.time()
if self._safe_upload(file_path, s3_key):
upload_time = time.time() - start_time
speed = (file_size / (1024 ** 2)) / max(upload_time, 0.001)
if self._record_operation(filename, file_hash, s3_key,
file_size, public_url, "UPLOAD"):
self.stats['uploaded'] += 1
pbar.write(
f"[{datetime.now().strftime('%H:%M:%S')}]{filename}\n"
f" {public_url}\n"
f" {speed:.2f} MB/s |{upload_time:.2f}s | "
f" {file_size / 1024:.1f} KB | {file_hash[:8]}..."
)
else:
self.stats['failed'] += 1
else:
self.stats['failed'] += 1
pbar.update(1)
except Exception as e:
self.stats['failed'] += 1
pbar.write(f"处理 {filename} 出错: {str(e)}")
pbar.update(1)
finally:
print("\n同步统计报告:")
print(f"文件总数: {self.stats['total']}")
print(f"新上传: {self.stats['uploaded']}")
print(f"已跳过: {self.stats['skipped']}")
print(f"已删除: {self.stats['deleted']}")
print(f"失败数: {self.stats['failed']}")
print(f"\n操作记录已保存到: {os.path.abspath(LOG_FILE)}")
if __name__ == "__main__":
print(f"自定义域名: {CUSTOM_DOMAIN}")
uploader = R2Uploader()
uploader.upload()三、使用Cloudflare Workers配置API调用
新建一个Workers,把下面这段代码粘进去,实现的是在R2储存桶生成一个manifest.json文件,记录文件夹里的所有文件名信息和对应访问网址。因为后面还要不断上传新的图片,所以每个小时更新一次列表。通过随机数返回manifest.json中的一个网址和图片名。
export default {
async fetch(request, env, ctx) {
const manifestKey = "manifest.json";
try {
const manifestObject = await env.xxxx.get(manifestKey); #这里的xxxx为你创建workers时候给的workers名称
if (!manifestObject || !manifestObject.body) {
return new Response("Manifest not found", { status: 500 });
}
const manifestText = await streamToText(manifestObject.body);
const files = JSON.parse(manifestText);
if (files.length === 0) {
return new Response("No images found", { status: 404 });
}
const random = files[Math.floor(Math.random() * files.length)];
const filename = decodeURIComponent(random);
const artistName = filename.split("_")[0];
const url = `https://sorahub.site/${random}`; #这里域名换成自己的域名(R2绑定的域名)
const responseBody = JSON.stringify({
url: url,
filename: filename,
artistName: artistName
}, null, 2);
return new Response(responseBody, { headers: { "Content-Type": "application/json" } });
} catch (err) {
return new Response("Failed to load manifest", { status: 500 });
}
},
async scheduled(event, env, ctx) {
const prefix = ""; #你文件在R2储存桶中的路径
let files = [];
let cursor;
do {
const listOpts = { prefix, limit: 1000 };
if (cursor) listOpts.cursor = cursor;
const res = await env.cos.list(listOpts);
if (res.objects) {
for (const obj of res.objects) {
const name = obj.key.split("/").pop();
if (name) {
const encodedName = encodeURIComponent(name);
files.push(encodedName);
}
}
}
cursor = res.list_complete ? undefined : res.cursor;
} while (cursor);
const manifestBody = JSON.stringify(files);
await env.cos.put(`${prefix}manifest.json`, manifestBody);
console.log(`Manifest updated with ${files.length} items.`);
}
};
async function streamToText(readable) {
const decoder = new TextDecoder();
let text = '';
for await (const chunk of readable) {
text += decoder.decode(chunk, { stream: true });
}
return text + decoder.decode();
}
